Amherst College Statistics and Data Science Colloquium Series (2025-2026)
Background
Talks in the Statistics and Data Science Colloquium are free and open to the public. They are intended to be accessible to a broad undergraduate audience with some background in statistics and data science. Junior and senior statistics majors are expected to attend talks in the SDS Colloquia (please reach out to Professor Nicholas Horton in case of conflicts).
More information about logistics and location can be found HERE.
Data Science Initiative (DSI)
Information about talks and and events sponsored by the Amherst College Data Science Initiative (DSI) can be found here.
Upcoming talks
Monday March 30th, 2026: Caroline Theoharides (Amherst College)
Associate Professor and Chair of Economics
Title: From “Brain Drain” to “Brain Gain”: How the Global Migration of Skilled Workers Shapes Economic Development in Low-Income Countries
- 4:15pm refreshments, 4:30pm talk
- Amherst College Seeley Mudd 207

Abstract: For decades, researchers have characterized the international migration of skilled workers from low-income countries to high-income countries as a one-way street that shrinks social economic growth in the world’s poorest regions by draining their available talent pool of doctors, nurses, scientists, and engineers. But “brain drain” isn’t inevitable. The individual incentive to move abroad for higher pay and personal advancement works to increase popular demand for higher education and professional development opportunities in low-income countries, ensuring a steady supply of talent in the local economy. And many migrants maintain strong connections with their countries of origin, regularly sending money back home during their prime working years and retiring to their birthplaces in old age. We are just beginning to appreciate just how much these examples of “brain gain” are stimulating economies across Africa, Asia, and Latin America. Join us to explore the statistics behind recent research that contribute to our understanding of the global economy in the 21st century.
Bio: Caroline Theoharides is an Associate Professor of Economics and Chair of the Economics Department at Amherst College. She received a Ph.D. in economics and public policy from the University of Michigan in 2014 and a B.A. in economics from Colby College in 2006. Her research focuses on labor markets in developing countries, using both quasi-experimental methods and randomized controlled trials. Caroline is particularly interested in topics surrounding international migration and its impacts on origin countries, child labor, and human capital accumulation. Her recent work has been published in outlets such as Science and the American Economic Review.
Past talks
Monday October 20, 2025: Troy Wixson (University of Massachusetts, Amherst)
Title: Neural classification of asymptotic (in)dependence
- 4:15pm refreshments, 4:30pm talk
- Amherst College Seeley Mudd 207

Abstract: The study of extremes allows us to learn about the tail of the distribution. This research is important when studying rare events that have outsized impacts like heatwaves, wildfires, and hurricanes. These problems are inherently multivariate in nature and capturing dependence in the tail is challenging. Classifying a data set as asymptotically dependent (ADep) or asymptotically independent (AInd) is a necessary early choice in the modeling of multivariate extremes. In this talk I will introduce the study of extremes and then perform a series of experiments to determine whether a finite sample has enough information for a neural network to reliably distinguish between these regimes in the bivariate case. These experiments lead to a new classification tool for practitioners which we call nnadic as it is a Neural Network for Asymptotic Dependence/Independence Classification. This tool accurately classifies over 95% of test datasets and is robust to a wide range of sample sizes. These experiments highlight that ADep and AInd models differ in whether the dependence completely decays in the limit, irrespective of the path of that decay.
Bio: Troy Wixson joined the UMass Department of Mathematics and Statistics as a Visiting Assistant Professor after completing his PhD in statistics at Colorado State University this past spring. Troy has research interests related to modeling tail dependence in multivariate extremes with environmental applications and Bayesian modeling of heterogeneous data to probabilistically identify genes associated with disease.
Monday September 22, 2025: Kate Shutta (Harvard University) and Katharine Correia (Amherst College)
Title: SpiderLearner: An ensemble approach to Gaussian graphical model estimation
- 4:15pm refreshments, 4:30pm talk
- Amherst College Seeley Mudd 207


Abstract: Gaussian graphical models (GGMs) are a popular form of network model in which nodes represent features in multivariate normal data and edges reflect conditional dependencies between these features. Currently available tools for GGM estimation require investigators to make several choices regarding algorithms, scoring criteria, and tuning parameters. An estimated GGM may be highly sensitive to these choices, and the accuracy of each method can vary based on structural characteristics of the network such as topology, degree distribution, and density. Because these characteristics are a priori unknown, it is not straightforward to establish universal guidelines for choosing a GGM estimation method. We address this problem by introducing SpiderLearner, an ensemble method that constructs a consensus network from multiple estimated GGMs.
In this talk, Dr. Shutta will present an overview of GGMs, the rationale and methodology behind SpiderLearner, and simulation results. Then, Dr. Correia will present an application of SpiderLearner to low dimensional data aimed at identifying mechanisms that contribute to adverse birth outcomes in the context of HIV infection and antiretroviral exposure.
Bio: Dr. Shutta is a postdoctoral fellow in the Department of Biostatistics at Harvard T.H. Chan School of Public Health. Her work leverages network models of multi-omic data to identify systems-level molecular characteristics associated with the development and progression of disease, including COPD, idiopathic pulmonary fibrosis, and cancer. Her translational goal is to use network features to discover targetable mechanisms of disease progression, thereby perturbing disease trajectories back towards healthy states.
Dr. Correia is a biostatistician interested in the development and dissemination of statistical applications for the medical and public health fields. Her applied research has focused on reproductive health and assisted reproductive technologies. She collaborates with clinicians and epidemiologists on research to elucidate links between modifiable risk factors and poor reproductive outcomes, enabling clinicians to better counsel patients and effectuating positive change in clinical practices.
Logistics
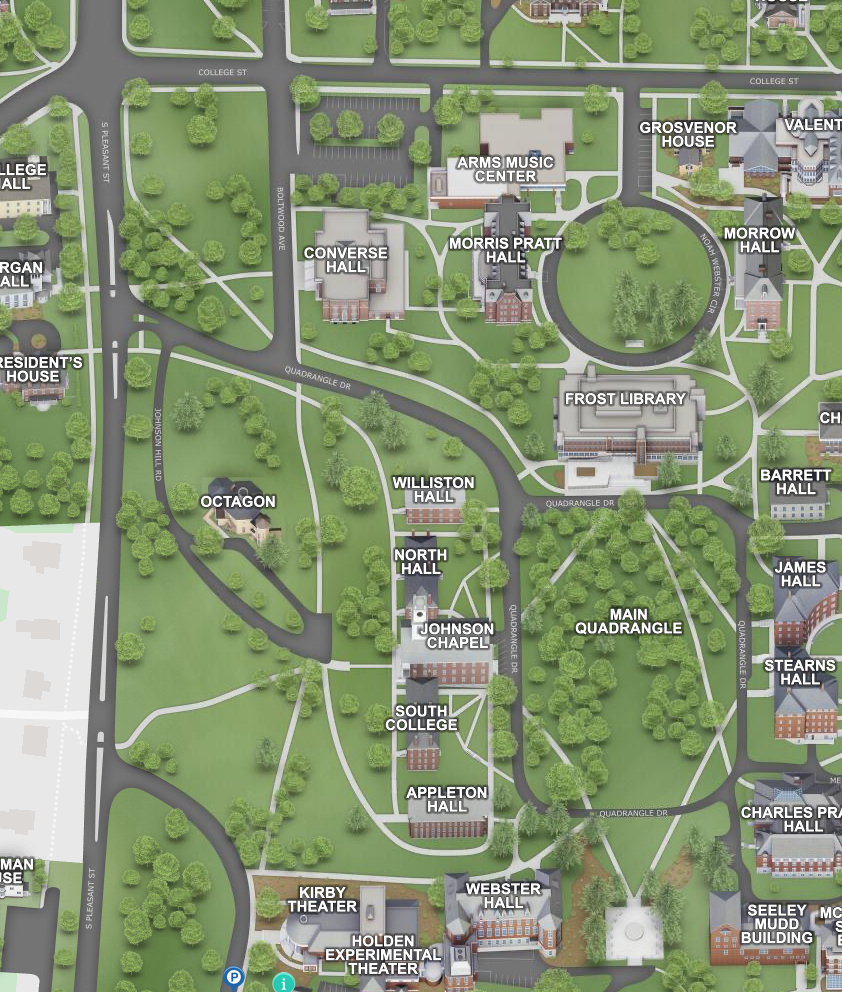
Seeley Mudd Hall is located at the southeast corner of the first year Quadrangle (31 Quadrangle Drive). Paid parking is available at the Amherst Town Common and Boltwood Drive (approximately 8 minute walk). PVTA Bus Service is available from the Amherst College Converse Hall stop (approximately 5 minute walk).
Last updated March 18, 2026
Copyright © 2025 Amherst College. All rights reserved.