Amherst College Statistics and Data Science Colloquium Series (2013-2018)
Here is a partial list of talks in the Amherst College SDS Colloquium Series.
September 23, 2013
Inferring Causation without Randomization
Casey Pattanayak (Wellesley College)
Thursday, November 14, 2013
Business Analytics Research at IBM
Bonnie Ray, IBM
As one of the largest IT companies in the world, IBM has been at the forefront of systems, software, and physical and mathematical sciences research for many decades. However, only in the last ten years has it begun to systematically apply advanced statistics and optimization capabilities to support its internal business decision making. In this talk, I’ll provide examples of how the Business Analytics and Math Sciences organization within IBM Research has partnered with other IBM divisions to enable data-driven business transformation. For one example, that of predicting performance of new business initiatives, I’ll discuss two different statistical approaches investigated, Regression Trees and Nearest Neighbors with Metric Learning, and discuss their performance from both a technical and a business perspective. I’ll also highlight some open problems with potential for future research.
Casey Pattanayak (Wellesley College)
Monday, March 24, 2014
Taking a Passion for Statistics to the Classroom, into the MOOC World and Back Again
Lisa Dierker (Wesleyan University)
Monday, October 20, 2014
Making Do With Less: The Mathematics of Compressed Sensing
Kurt Bryan (Rose-Hulman Institute of Technology)
Monday, February 15, 2015
Oh the Places You’ll Go: The Surprising Complexity of Statistics’ Most Basic Model
Taylor Arnold, AT&T Laboratories
A Bernoulli distribution describes a process which has only two outcomes. Despite the simplicity, it is used in a wide array of applications including a simple coin toss, the outcome of a sporting event, weather models, and the winner of an election. A careful analysis of the Bernoulli distribution also raises a number of theoretical questions leading to topics such as Bayesian inference, minimaxity and estimator theory. Fortunately, the relatively uncomplicated nature of the Bernoulli model allows such questions to be studied without the advanced mathematical machinery required for a more general treatment. This talk will explore these practical and theoretical considerations, with a focus towards the `big questions’ which continue to guide modern statistical research. Two real datasets, from baseball and medicine, will be used throughout to guide the discussion.
Thursday, October 22, 2015
Causal Inference: Identifying Subgroups by their Response to Treatment
Sarah Anoke, Department of Biostatistics, Harvard T.H. Chan School of Public Health
Abstract: Causal inference is a field of statistics focused on
measuring a particular type of relationship between two variables.
Referring to these two variables as the
treatment’ and theoutcome’, we consider the value that an
individual’s outcome would take if the treatment was present, and the
value that the individual’s outcome would take if the treatment was
absent. The difference in these two potential outcomes is the treatment
effect. Every individual has their own individual treatment effect
(ITE). But because only one of these two potential outcomes is
observable, ITEs cannot be estimated from observed data. To overcome
this problem, the average outcome among a group of individuals unexposed
to treatment is subtracted from the average outcome among a group of
individuals exposed to treatment, yielding an average treatment effect
(ATE). It is of interest to identify subgroups for which the
subgroup-specific ATE is very different from the overall ATE. Knowing
the overall ATE is arguably misleading; we would prefer to know that the
drug has no effect within women but a dramatic effect within men. How
then, can the data tell us which subgroups respond particularly well or
poorly to treatment, without advance knowledge of these subgroups?
Friday, October 30, 2015
Statistical tools and challenges for monitoring migratory birds
Emily Silverman (Division of Migratory Bird Management, U.S. Fish & Wildlife Service)
Federal management of migratory birds began 100 years ago, when the United States signed the 1916 Convention for the Protection of Migratory Birds with Great Britain (for Canada). These protections were codified in the Migratory Bird Treaty Act (MBTA) of 1918, which now covers over 800 species of birds, and stands as one of the earliest U.S. environmental laws. The evolution of management approaches since the MBTA has led to the development of monitoring programs and quantitative methods in wildlife science. I will present the history of bird monitoring and statistical methods for population assessment and will discuss new approaches, challenges, and how a solid understanding of statistical concepts is essential for informed management. Drawing on examples from my own work, I will highlight the interdisciplinary skills needed to operate effectively as a scientist and statistician in a resource management agency. As our ability to collect information about the natural world expands in an increasingly digital world, the need for innovative, technically-adept wildlife scientists is expanding.
Wednesday, November 11, 2015
Statistics and Policy Making – The Case of Greece
Andreas Georgiou (Amherst College)
Monday, November 16, 2015
Statistical Analysis of Big Genetics and Genomics Data
Xihong Lin (Harvard University): this talk was also part of the Connecticut Valley Colloquium Series
The human genome project in conjunction with the rapid advance of high throughput technology has transformed the landscape of health science research. The genetic and genomic era provides an unprecedented promise of understanding genetic underpinnings of complex diseases or traits, studying gene-environment interactions, predicting disease risk, and improving prevention and intervention, and advancing precision medicine. A large number of genome-wide association studies conducted in the last ten years have identified over 1,000 common genetic variants that are associated with many complex diseases and traits. Massive targeted, whole exome and whole genome sequencing data as well as different types of -omics data have become rapidly available in the last few years. These massive genetic and genomic data present many exciting opportunities as well as challenges in data analysis and result interpretation. They also call for more interdisciplinary knowledge and research, e.g., in statistics, machine learning, data curation, molecular biology, genetic epidemiology and clinical science. In this talk, I will discuss analysis strategies for some of these challenges, including rare variant analysis of whole-genome sequencing association studies; analysis of multiple phenotypes (pleiotropy), and integrative analysis of different types of genetic and genomic data.
Monday, February 22, 2016
Protein Data Analysis at Scale in R
Aaron Coburn (Amherst College)
Monday, April 11, 2016
Statistics and Bayesian Inference in Neuroscience
Rob Kass (Carnegie Mellon University)
Monday, October 17, 2016
Communicating the Value of Statistics
Jessica Utts (University of California, Irvine)
Friday, October 28, 2016
Did the Military Interventions in the Mexican Drug War Increase Violence?
Valeria Espinosa (Google)
Friday, February 3, 2017
Activity Monitors: Some interesting data and challenges
John Staudenmeyer (University of Massachusetts, Amherst)
Thursday, September 21, 2017
Lessons for official statistics production around the world from the experience of Greece
Andreas Georgiou (Amherst College)
Monday, November 27, 2017
Lessons for official statistics production around the world from the experience of Greece
Joseph Hogan (Brown University)
Tuesday, January 16, 2018
Spurring Innovation and Diversity in Interdisciplinary Biomedical Data Science through Hackathons in Puerto Rico
Patricia Ordonez (University of Puerto Rico Río Piedras)
Tuesday, February 6, 2018
Estimating the Impact of Cluster-Based Interventions
Laura Balzer (University of Massachusetts, Amherst)
Tuesday, October 23, 2018
Data Science for Political Campaigns
Matthew Rattigan (University of Massachusetts, Amherst)
In recent years, presidential campaigns have become increasingly quantitative in nature. Once dominated by a small group of backroom strategists making gut decisions, modern campaigns have become increasingly reliant on data-backed decision support. Over the past two decades, this “moneyball-ization” of politics has transformed the way campaigns are run and how resources are allocated. In this talk, I will describe my experiences working for the Analytics Department of Obama For America during the 2012 election cycle. As a digital analyst, I worked alongside political scientists, statisticians, and physicists on problems ranging from social media analytics to quantifying the effects of communications and messaging. In addition, I’ll touch upon some of the privacy issues brought up in the 2016 election cycle.
Thursday, November 1, 2018
Inference from Multivariate Respondent-Driven Sampling Data
Krista Gile (University of Massachusetts, Amherst)
Respondent-Driven Sampling is type of link-tracing network sampling used to study hard-to-reach populations. Beginning with a convenience sample, each person sampled is given 2-3 uniquely identified coupons to distribute to other members of the target population, making them eligible for enrollment in the study. This is effective at collecting large diverse samples from many populations. Due to the complexity of the sampling process, inference for the most fundamental of population features: population proportion, is challenging, and has been the subject of much work in recent years, typically using only data on local network size and the variable of interest. This talk focuses on work that considers inferential goals addressed using multiple variables measured on participants. We describe using data on local network composition for a variable biasing recruitment to adjust for preferential recruitment, semi-parametric testing for bivariate associations in the RDS dataset, and methods for clustering RDS participants based on covariate and referral data.
Monday, November 5, 2018
Data Mining: Tasks, Systems, Challenges, and Research Directions
Matteo Riondato (incoming faculty in CS at Amherst College)
In this talk, I describe the field of Data Mining (DM) from the point of view of a researcher in this discipline. Starting from my definition of DM, I give examples of DM tasks for different kinds of data, commenting on available systems for DM and discussing the algorithmic challenges in DM. I show how my research tackles some of these challenges and list the interesting questions I plan to answer in the near future with the help of Amherst students.
Background
Talks in the Statistics and Data Science Colloquium are free and open to the public. They are intended to be accessible to a broad audience with some background in statistics and data science. Junior and senior statistics majors are expected to attend talks in the SDS Colloquia. Please reach out to Professor Nicholas Horton in case of conflicts.
Logistics
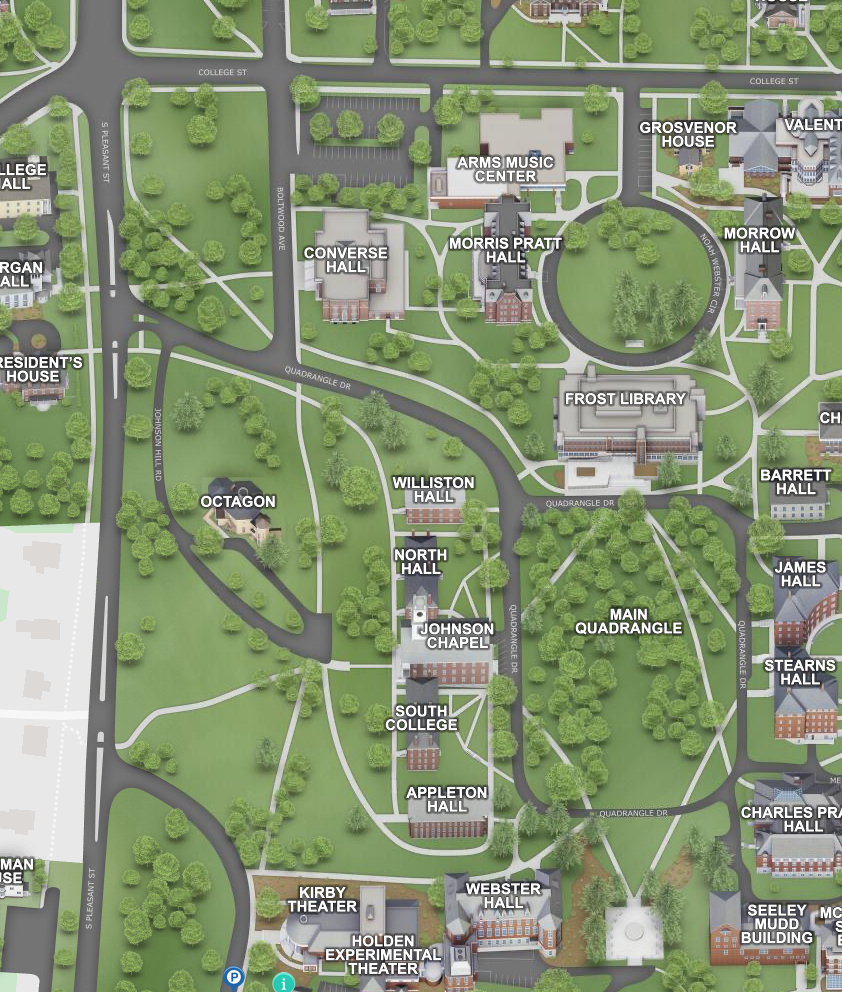
Seeley Mudd Hall is located at the southwest corner of the first year Quadrangle (31 Quadrangle Drive). Paid parking is available at the Amherst Town Common and Boltwood Drive (approximately 8 minute walk). PVTA Bus Service is available from the Converse Hall stop.
Copyright © 2025 Amherst College. All rights reserved.