Amherst College Statistics and Data Science Colloquium Series (2020-2021)
Thursday, October 1, 2020
How Statistics Can Make an Impact: A case study describing the filing story of ZINPLAVA
Alison Pedley (Merck)
Statistics plays a big role in drug development in the design and analysis of clinical trial data. This case study explores an example where statistics made a huge impact and allowed for a deeper understanding of the data. More specifically, ad-hoc sensitivity analyses designed and conducted by the statistical team proved to be critical to the product’s approval. Two large, phase 3 trials were conducted to demonstrate the superiority of ZINPLAVA over placebo. Though the primary endpoint was met in both studies, another important endpoint had conflicting results. In one study, ZINPLAVA was significantly higher and in the other study, it was significantly lower. This talk will also give a brief overview of the drug development process and the role of a statistician at a large pharmaceutical company in clinical development.
Thursday, October 15, 2020
Regression Methods for Network Indexed Data: Modeling Occurrences of Burglary and Identifying Correlates of Injection Drug Use Cessation
Elizabeth Upton (Williams)
We begin by defining and providing examples of network-indexed data. We then turn to two applications: modeling occurrences of residential burglary in Boston, MA and identifying network predictors of injection drug use cessation among a group of drug users in rural Kentucky. We discuss the graph Laplacian, a hierarchical regression model, and generalized estimating equations along the way.
Thursday, November 12, 2020
Migraine - More than just a Headache
Pamela Rist (Harvard)
Nearly 15% of the US population experiences migraine headaches and migraine ranks as one of the leading causes of disability worldwide. In this talk, I will discuss some of our research on the health effects of migraine, including the association between migraine and cardiovascular disease risk factors, stroke, and cognitive decline. I will also provide an overview of some of the unique methodological challenges facing migraine researchers and highlight some future research directions.
Thursday, March 4, 2021
Statistical and Computational Methods for Whole Genome Sequencing Studies
Sheila Gaynor (Harvard)
Many complex diseases have a notable genetic component; however, for most diseases and traits, a limited number of associated genetic variants have been identified. Current large-scale whole genome sequencing efforts allow for the analysis of genetic associations across millions of low frequency and rare variants using large samples (100K+). To analyze rare variants, variance component tests aggregating multiple variants are commonly implemented to improve statistical power. However, such generalized mixed model-based methods are nonetheless limited by low statistical power and significant computational cost. In this talk, I discuss methods for rare variant tests to analyze large samples incorporating functional data in a dynamic weight scheme to improve power. I introduce cloud-based computational tools that implement such methods using a scalable framework. Lastly, I discuss the application of these methods to analyze data on heart, lung, blood, and sleep disorders from the NHLBI Trans-Omics for Precision Medicine (TOPMed) Program.
Thursday, April 8, 2021
Uncertainty and the Response to COVID-19
David Kline (The Ohio State University)
The COVID-19 pandemic has impacted all of our lives and reporting on epidemiological data has become almost a routine, daily occurrence. Since early in the pandemic, I have been on the OSU Comprehensive Monitoring Team that has been advising the Ohio Department of Health. One important theme throughout this work has been operating under uncertainty. As with any novel disease, there was and still is uncertainty about the disease itself. However, there is also uncertainty about the data that we can collect to try to understand rates of infection across space and time and to identify emerging areas of concern. It is critical to consider this uncertainty within the decision-making process. During this talk, I will discuss several areas where I have contributed to the response to COVID-19 including a seroprevalence study, surveillance, and an excess deaths analysis. I will particularly focus on the importance of thinking beyond the data that are observed to consider the context and the quality of what are observed. Through these examples, I will highlight important contributions of statistical and epidemiological methods and thinking.
Thursday, April 22, 2021
Background
Talks in the Statistics and Data Science Colloquium are free and open to the public. They are intended to be accessible to a broad audience with some background in statistics and data science. Junior and senior statistics majors are expected to attend talks in the SDS Colloquia. Please reach out to Professor Nicholas Horton in case of conflicts.
Logistics
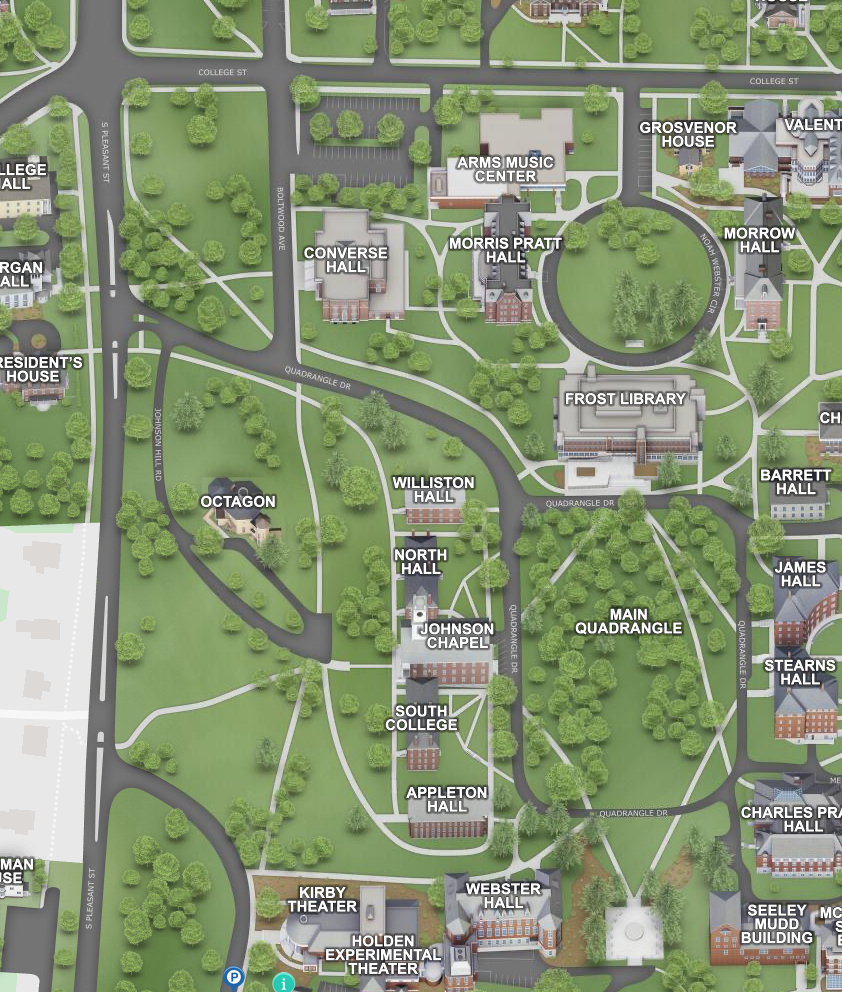
Seeley Mudd Hall is located at the southwest corner of the first year Quadrangle (31 Quadrangle Drive). Paid parking is available at the Amherst Town Common and Boltwood Drive (approximately 8 minute walk). PVTA Bus Service is available from the Converse Hall stop.
Copyright © 2025 Amherst College. All rights reserved.